

Artificial Intelligence (AI) technology has advanced significantly, with Large Language Models (LLMs) playing a crucial role in how machines understand and respond to human language.
LLMs are the foundation of many sophisticated AI communication systems in use today. This article will explore the different types of LLMs and how they work.
LLM:
LLM stands for “Large Language Model,” which refers to a class of NLP models designed to understand, generate, or predict human language.
Language models analyze and understand written content like sentences, paragraphs, or documents.
They learn to represent the structure and meaning of language and can be used for various tasks, such as translation, text generation, sentiment analysis, and question-answering.
Traditional language models, such as
- Recursive Neural Tensor Network (RNTN): The Recursive Neural Tensor Network is a neural network model designed to work with structured data, such as parse trees in NLP.
- Recurrent Neural Networks (RNNs): RNNs are a class of neural networks that process data sequences by maintaining hidden states and using them to process subsequent elements in the sequence.
- Long Short-Term Memory (LSTM): LSTM is a specific type of RNN that addresses the vanishing gradient problem by incorporating memory cells and gating mechanisms.
- Gated Recurrent Units (GRUs): GRUs are another type of RNN variant that share some similarities with LSTMs but have a more straightforward structure.
- Hierarchical Neural Network (HNN): The Hierarchical Neural Network is designed to capture hierarchical structures in text data.
However, transformer-based models have gained significant popularity in recent years due to their superior performance on various NLP tasks.
Transformer LLMs:
Transformer uses attention mechanisms to weigh the relevance of words in the input data, aiding in predicting the next word.
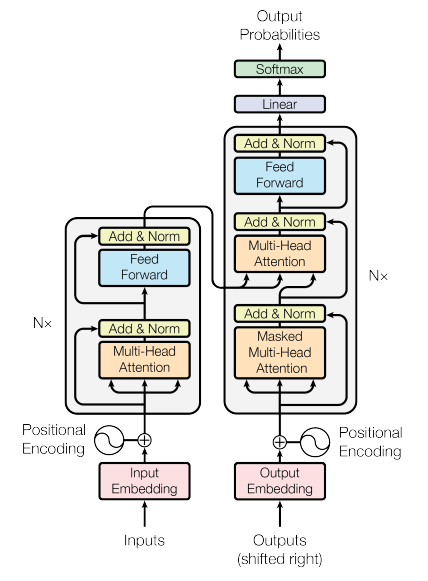
The transformer models consist of two main components: the encoder, which reads and interprets the input text, and the decoder, which generates a response or continuation. These models are powered by multiple layers of self-attention and point-wise, fully connected layers, allowing them to handle complex interactions between words and their context.
Developed by Vaswani et al. in the paper “Attention is All You Need” (2017)[1706.03762] Attention Is All You Need (arxiv.org), the Transformer model introduced the concept of the “attention mechanism”, which allows the model to weigh the importance of certain words in a sentence when making predictions.
Attention is all you needclick image to see paper
Here are a few key components of Transformers:
- Encoder and Decoder: Transformers have two main parts: an encoder, which reads the input data (e.g., a sentence in English), and a decoder, which generates the output (e.g., the translated sentence in Spanish).
- Attention Mechanism: This is one of the critical innovations of the Transformer model. The attention mechanism allows the model to focus on different parts of the input sequence when generating each word in the output sequence. This technique helps the model handle longer sentences better and remember more contextual information.
- Self-Attention: In this particular type of attention mechanism where the model calculates the relevance of each word in the sentence to the current word being processed. This allows the model better to understand the context of each word in the sentence.
- Positional Encoding: Since the Transformer model doesn’t inherently understand the order of words in a sequence, it uses positional encodings to inject information about the relative or absolute position of the words in the sequence.
- Layer Stacking: Both the encoder and decoder are composed of a stack of identical layers. Each layer in the encoder performs a self-attention operation and a feed-forward operation. Each layer in the decoder performs self-attention, encoder-decoder attention, and a feed-forward operation.
How Transformer-LLMs Work:
LLMs work by training on a large corpus of text data, learning to predict the next word in a sentence.
Here’s a simplified step-by-step guide to how these models are trained:
1. Data Collection: In the first step, we collect much-written information. This information can come from books, articles, websites, or other sources. This dataset is used to train the model.
2. Tokenization: The text data is then broken down into smaller units, typically called tokens, which could be as short as one character or as long as one word.
3. Embedding: Each token is converted into a vector—a list of numbers a computer can understand and process. This vector aims to capture the semantic meaning of the word.
4. Training the Model: The model is then trained on this data using supervised learning. In this case, supervised learning means the model is given a set of inputs (tokens from the text data) and taught to predict a specific output (the following token).
5. Self-Attention Mechanism: The self-attention mechanism is a crucial component of transformer models, enabling them to evaluate the significance of each word (token) in the context of the other words in a sentence. By doing so, the model can focus on the most relevant information and make more accurate predictions. Let’s explore how the self-attention mechanism works in two sentences:
- “Man in the bank”: In this example, the word “bank” can have multiple meanings, such as a financial institution or the side of a river. When predicting the word “bank,” the self-attention mechanism will weigh the importance of each token in the context of the whole sentence. It will likely assign higher importance to “man” and “in” to determine that the word “bank” here refers to a financial institution. This is because the combination of “man in” strongly associates with a person’s presence within a building.
- “Man at the bank of the river”: Similarly, the word “bank” has multiple possible interpretations in this example. When predicting the word “bank,” the self-attention mechanism will pay attention to the surrounding tokens, especially “man” and “at the bank of the river.” In this case, the context provided by “at the bank of the river” will carry more weight, leading the model to understand that “bank” refers to the side of a river.
By assigning different weights to each token based on their importance in the context, the model can make more informed predictions and better comprehend the nuances of language.
6. Prediction: The model can generate new text by predicting the next word in a sentence after training. This is done by feeding the model a sequence of words and having it output probabilities for the next word. The model selects the word with the highest probability, adds it to the sequence, and repeats the
Fine-Tuning LLMs:
Fine-tuning is training a pre-trained model on a new, specific task.
It’s similar to improving a skill by practising it specifically and purposefully.
Once the base LLM has undergone pre-training, it is possible to further refine it by continuing the training process using a more specialized dataset and adjusting the weights acquired during pre-training to enhance performance on the specific task.
Here are the steps to fine-tune an LLM:
1. Select a pre-trained model – When selecting a pre-trained model, it is vital to choose one suitable for the specific task. To achieve this, one must search for a model that has undergone training on a similar task or a varied dataset.
2. Prepare the dataset – The data should align closely with the task. It’s crucial to clean and preprocess the data for optimum results properly.
3. Fine-tune the model – The pre-trained model is then trained on the task-specific data using backpropagation and gradient descent, adjusting the model’s weights to minimize the loss function.
Transformer-based Large Language Models:
LLMs come in a variety of architectures, each with its unique aspects. The most prominent include:
1. GPT (Generative Pretrained Transformer) – GPT models, including GPT-4, are transformer-based and leverage unsupervised learning to generate human-like text. They’re designed to predict subsequent words within a given context.
2. BERT (Bidirectional Encoder Representations from Transformers) – BERT examines context from both directions (left and right of a word) in a sentence, improving the model’s understanding of context.
3. Transformer-XL – This model handles long-term dependency in sequences by remembering past information, effectively bridging the gap between previously processed segments.
4. XLNet – XLNet overcomes BERT’s limitations by leveraging the benefits of both autoregressive and autoencoding methods, allowing the model to learn the context of a word concerning all other words rather than just those preceding it.
5. T5 (Text-to-Text Transfer Transformer) – T5 simplifies handling different tasks by converting every task into a text generation problem.
6. CTRL (Conditional Transformer Language Model) – CTRL generates specific types of text using control codes, enabling fine-grained control over the generated text.
7. RoBERTa – RoBERTa is a version of BERT that modifies key hyperparameters, removing the next-sentence pre-training objective and training with much larger mini-batches and learning rates.
8. ALBERT – ALBERT is a lite BERT that allows for even greater scalability by factorizing the embedding layer and sharing parameters across the hidden layer.
In conclusion, Large Language Models form a vital part of our AI-enabled world, driving advancements in natural language processing and understanding.
They’re transforming industries and functions, from customer service to data analytics, and when combined with innovative systems like Langchain, they promise an exciting future for AI and language technology.









